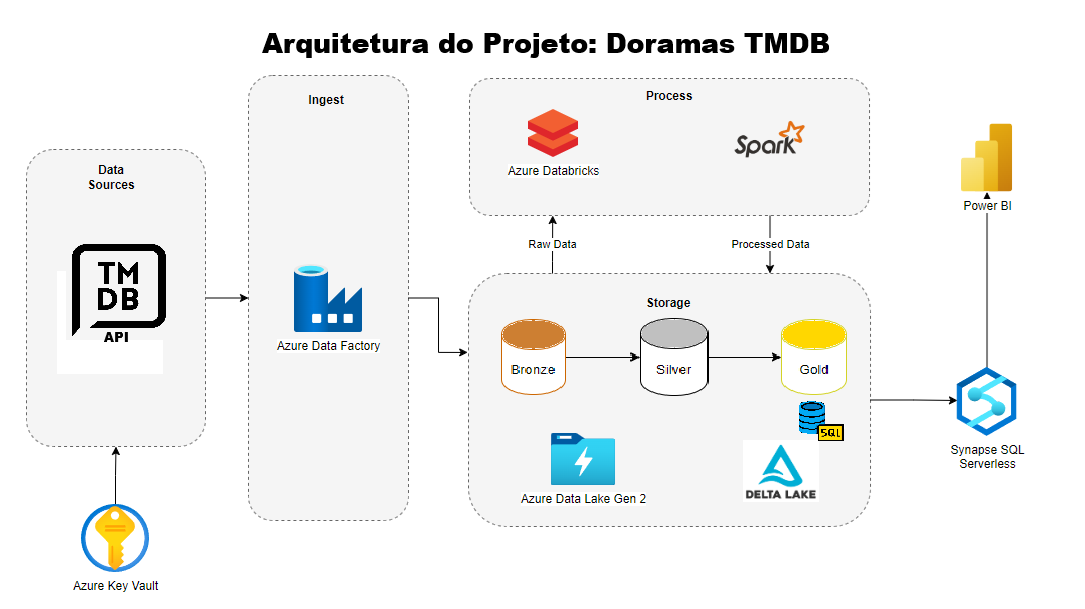
Este projeto demonstra a construção de um pipeline de dados completo, desde a ingestão de dados brutos de uma API pública até a criação de um dashboard interativo. O objetivo foi transformar dados sobre dramas coreanos (Kdramas) da API do The Movie Database (TMDB) em um conjunto de dados analítico, estruturado e pronto para BI, utilizando uma arquitetura Data Lakehouse moderna na nuvem Microsoft Azure.
O resultado final é um dashboard interativo, construído com Streamlit e implantado na web, que permite a exploração e análise das tendências e popularidade dos Kdramas lançados nos últimos anos.
A solução foi implementada seguindo a arquitetura Medalhão (Bronze, Silver, Gold), garantindo a qualidade, governança e rastreabilidade dos dados em cada etapa do processo.
- Plataforma Cloud: Microsoft Azure
- Armazenamento de Dados:
- Azure Data Lake Storage (ADLS) Gen2: Para armazenar os dados nas camadas Bronze, Silver e Gold.
- Delta Lake: Formato de tabela para garantir confiabilidade e performance no Data Lake.
- Azure SQL Database: Atuando como Data Warehouse (camada de serviço) para o dashboard.
- Processamento de Dados:
- Azure Databricks: Plataforma central para o desenvolvimento dos pipelines.
- Apache Spark (PySpark): Motor de processamento distribuído para as transformações de dados.
- Pandas: Usado para prototipação e manipulação de dados local.
- Segurança:
- Azure Key Vault: Para gerenciamento seguro de segredos (chaves de API, senhas de banco de dados).
- Governança:
- Unity Catalog (Databricks): Para gerenciar o acesso aos dados no Data Lake.
- Visualização de Dados e Aplicação Web:
- Streamlit: Para a construção e deploy do dashboard interativo.
- Power BI: Alternativa de ferramenta de BI para consumir os dados do SQL Server.
- Orquestração:
- Databricks Workflows: Orquestrador nativo para automatizar a execução dos notebooks.
- Apache Airflow (com Docker): Utilizado na fase de desenvolvimento local para orquestração dos scripts Python.
- Pipeline ETL Completo: Implementação de um pipeline de dados end-to-end, da extração à visualização.
- Arquitetura Medalhão: Organização dos dados em camadas Bronze (brutos), Silver (limpos) e Gold (agregados), garantindo qualidade e governança.
- Data Lakehouse: Uso do Delta Lake sobre o ADLS para combinar a flexibilidade de um Data Lake com a confiabilidade de um Data Warehouse.
- Dashboard Interativo: Uma aplicação web construída com Streamlit que permite filtrar e analisar os dados de Kdramas por ano, gênero, e popularidade.
- Gerenciamento de Segredos: Configuração segura de credenciais utilizando Azure Key Vault e Databricks Secrets.
- Deploy na Web: Implantação da aplicação Streamlit na nuvem (Render.com) usando Docker para um ambiente consistente e reproduzível.
kdrama_analytics_project/
├── kdrama_dashboard/ # Projeto da aplicação Streamlit
│ ├── .streamlit/
│ │ └── secrets.toml.example # Exemplo do arquivo de segredos
│ ├── Dockerfile
│ ├── requirements.txt
│ └── app.py
├── dags/ # (Opcional) DAGs do Airflow para desenvolvimento local
├── notebooks/ # Notebooks do Databricks (Bronze, Silver, Gold)
├── src/ # (Opcional) Scripts Python originais para desenvolvimento local
└── README.md
-
Pré-requisitos:
- Python 3.9+
- Conta no Azure com os recursos do projeto devidamente configurados (ADLS, SQL DB, Key Vault, Databricks).
- Pipeline de dados no Databricks já executado para popular a camada Gold no SQL Server.
- Microsoft ODBC Driver for SQL Server instalado na sua máquina.
-
Clone o repositório:
git clone [https://github.com/](https://github.com/)[seu-usuario]/[seu-repositorio].git cd [seu-repositorio]/kdrama_dashboard -
Crie e ative um ambiente virtual:
python -m venv venv # Windows venv\Scripts\activate # macOS/Linux source venv/bin/activate
-
Instale as dependências:
pip install -r requirements.txt
-
Configure suas credenciais:
- Crie uma pasta
.streamlitdentro dekdrama_dashboard. - Dentro dela, crie um arquivo
secrets.tomlcom suas credenciais do Banco de Dados SQL do Azure. Este arquivo não deve ser enviado para o Git.
# .streamlit/secrets.toml [database] server = "seu_servidor_sql.database.windows.net" database = "seu_banco_de_dados" username = "seu_usuario" password = "sua_senha" driver = "ODBC Driver 18 for SQL Server"
- Crie uma pasta
-
Execute a aplicação:
streamlit run app.py
Seu navegador abrirá automaticamente com o dashboard!
- Agendar a execução do pipeline no Azure com Databricks Workflows para atualização diária.
- Implementar testes de qualidade de dados com Great Expectations ou
dbt tests. - Adicionar mais visualizações e análises ao dashboard.
- Criar um pipeline de CI/CD com GitHub Actions para automatizar o deploy do dashboard.
Este projeto está sob a licença MIT. Veja o arquivo LICENSE para mais detalhes.